
帖子: 学习阶段总结
工作流程
1、Gerrit仓库
-
Gerrit网页操作,查看、处理代码和发送reviewer等。
-
git reset重做 git revert以commit的方式放弃某次更改
-
学习复杂的git命令:cherry-pick、git commit –amend、git rebase,已经能熟练的中处理和提交git项目。
2、BUG维修
- 熟悉Redmine和Gerrit的BUG上报和维修流程,根据不同结论添加报告。
- 简单的BUG、LOG搜索和定位,知道哪部分的代码和哪些问题是我们处理。
Linux图形栈
- Xorg-xserver:
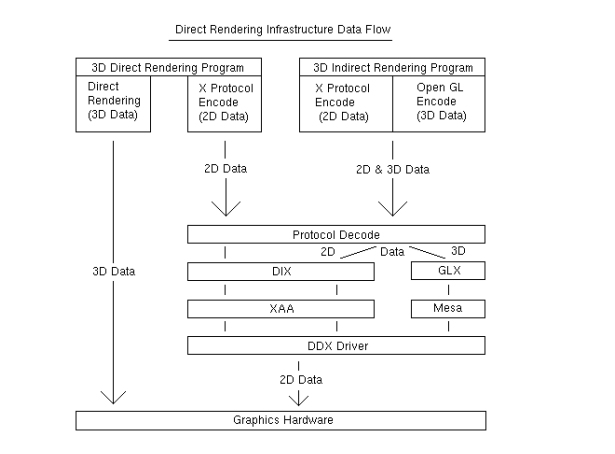
X的驱动包括软件部分DIX和硬件部分DDX,在X11/module/driver文件夹下有硬件相关driver,2D driver驱动模块为arise_drv.so,3D driver是arise_dri。
Xorg在初始化会probe显示device驱动,如果没找到就会依次找:fbdev(默认framebuffer)、vesa、KMS(有glamor加速),在xorg.conf中有X的初始配置,-10表示显卡相关。
加载显示驱动后,Xorg加载输入设备(xinput)。
DDX代码在xorg源码的xfree86文件夹下,各厂商DDX驱动的实现格式相似。Xorg的log在var中。
窗口的专用屏幕外缓冲区(后缓冲区、假前缓冲区、深度缓冲区、模板缓冲区等)的分配由Xserver gbm本身完成,合成窗口管理器将其用作合成作为最终的屏幕后缓冲。
Xorg 2D driver只是xserver的一个模块,主要实现2D加速画点和线。我们的驱动里面实现了一套私有的rxa加速函数,以及通过glamor3D加速。 2d driver: drm向用户态发送三个事件vblank、 pageflip complete、in crtc
Xorg loadmod的过程:先调FindModule找到.so 再调dlopen 组装cx4ModuleData结构,调用dlsym(fd,function) 印象中是先加载所有的drv driver然后再删 判断依据是xf86IsEntityPrimary 整个流程都在DoConfigure中 所有的初始化阶段都看这个函数
- drm:(man drm)为与dri联合使用,上层显示服务提供接口(/dri/card0,/dri/renderD128),在用户态对应LibDRM库,底层就是显卡driver代码,通过一系列
ioctl(或者ioctl包装的辅助函数)实现用户态程序到内核驱动最后操作硬件,使用户态程序可以访问显存、DMA和OB。drm设备继承了pcie设备。drm中的gem模块实现buffer的管理,更底层的实现我们公司自己实现的而不是ttm。

对于drm的ioctl由drm自己实现 在drm_ioctl。c中 fd是走的fdtable 而dma handle在radix_tree申请
-
dri:dri驱动由硬件厂商实现,驱动程序可以直接访问硬件,Xorg可以通过OGL走dri实现硬件加速,利用3D驱动绘制2D图像(glx)。通过gdb可以追踪调用路径。
-
LibGL库:是实现了OpenGL的编程接口,用户使用LibGL库提供的开发接口开发OpenGL应用程序,对用户屏蔽了底层的实现细节,其实就是向图形驱动下发OpenGL的调用。
-
KMS:完成显卡配置,能直接操作底层硬件实现显示,不依赖Xserver。但是通过KMS写显示代码更复杂,需要定义所有组件的行为,找到所有可以用路径并选择一条, 也需要代码实现buffer flip。
-
bit-blit:块传输图,将图像从内存中的一个区域快速地复制到另一个区域生成一个副本,gpu可通过它获得数据。
-
fence:标记一个GPU pipeline事件,用于cpu与gpu的同步。当cpu写入一个fence,所有关联的ip核上的ringbuffer都会flush cache,防止数据被覆盖。 多个渲染命令作为一个packet提交到ringbuffer,提交的IT_BODY部分既可以是渲染命令也可以是命令的地址。提交一次cpu渲染命令后,绑定fence回调函数发送到gpu,并 查询fence状态。
-
DMAbuffer:dmabuf是buffer与file的结合,即dma-buf既是块物理buffer,又是个file。应用程序可以通过file属性直接写数据,GPU可以在地址空间直接读。 cpu访问dmabuffer通过kmap和vmap,外设访问也有特定的函数,通过mmap映射给应用程序。
-
MMIO:将外设内存或者IO映射到cpu可见的物理地址,让cpu访问外部内存和io跟访问内存一样。
-
PCImemory:snoop(不用管) unsnoop(手动flush)
-
IOMMU:外设的虚拟地址转换,外设访问内存跟cpu一样访问虚拟地址。
-
sysfs:对sysfs相关的实现和函数基本了解,能定义并使用文件节点,熟悉linux这部分文档的规范。
-
power-gating/dvfs:amd上的通过level来设置,大范围给了performance、battery、balance调节clock的上限,可以通过手动调节电压和电源的level。 004上主要由pg_cg-gating和dvfs两部分,pgcg auto模式通过硬件idle计数调节,manual模式通过driver的task密度调节。dvfs通过checksize和threshold 两个参数调节,在一个checksize中工作状态大于threshold的上限就加,小于下限就减。
-
Mesa:开源图形库,利用软件实现了图形api,硬件的usermod驱动和mesa结合使用。Gallium3D: Gallium3D是Mesa的一部分,是一个开发3D图形驱动的框架。 glvnd是nvidia的开源项目,加glvnd层将openglapi分配给具体的实现。
GLENFLY
-
驱动代码架构:xf86-video-zx是2Ddriver,CIL2是中间层结构,E3K中是硬件层代码,还有linux相关代码等。
-
Linux文件夹下的core层代码是核心代码,e3k是chip层代码,对内核层提供了函数接口。vidmm是内存分配和管理的代码,vidsch是任务调度和事件处理相关的代码, 还有CM上下文相关代码,中断处理和display相关代码。
-
CM:上下文管理,其实就是一个大结构体绑定了显卡资源。
-
VidMM:
概述:负责管理allocation的生命周期、将物理地址映射到虚拟地址等操作。
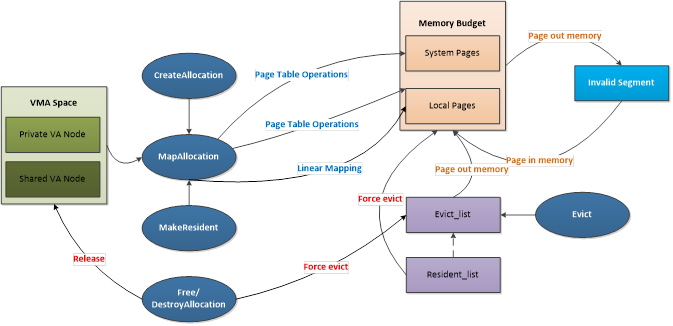
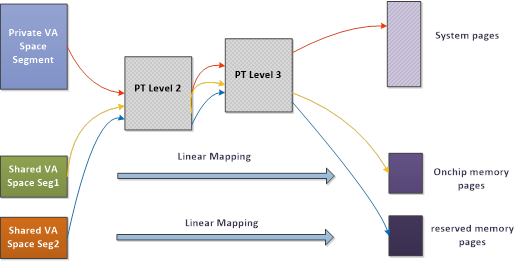
地址空间管理:将显存分为私有和共享空间,一个独立的部分叫做zone,zone有特定的分配格式。初始化zone后分配bigmap并填page table, 根页表PTE存在TTBR寄存器,进行MMIO和DMA操作时就会查表。
reserved_vma:记录kmd资源信息,例如dma fence page等 。
segment内存用于kernel mode资源,包括一些全局资源,如fence buffer、CM buffer,并包括一些内部使用资源,比如页表缓冲区。
VM操作:在初始化阶段分配的zone上allocate一段内存(node list)->分配物理页,填3级页表。(文档中有虚拟内存空间计算表)->vma-space更新page directory让gpu能直接detect页表
GPU allocation lifeCycle:是否共享->是否evict(页置换)->引用计数为0 销毁->检查shared引用->销毁对应的物理内存和页表。
内存数据结构:pa rbt - va rbt ,heap - buddy(合并)
GPU vma-space: 就是指当前的vmid能指示的空间 GPU page fault:在初始化已经将空间和各级pte全部准备好了,不需要中断服务 GPU vmid 进程vmid1~15会复制vmid0(kernel)
-
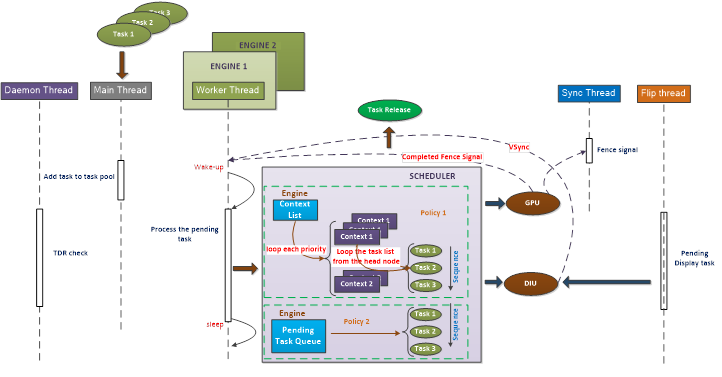
VidSch:
概述:决定哪个任务可以被GPU执行,何时执行,比如渲染、同步、显示。
TDR:探测硬件状态,别让硬件停了。
线程:主线程(添加工作队列),工作线程(每个engine都有),守护线程,同步线程(fence,flip)
scheduler管理:一个adapter一个,各自engine都有(管理ringbuffer)。scheduler需要内存所以依赖vidmm部分。
vm id?:虚拟内存编号,各种scheduler entity分配内存时都有vmid。
task:一个任务包括多个命令,可由多个初始task组成一个package。常见的task包括render、paging(页置换 fill)、sync(fence)、wait、signal、display等等,task结构体中专门指出dma的描述和类型。 生命周期由创建、等待、执行、释放,其中包括fence和fence回调。
fence:wait fence的task只要等到比它大的fence就会wakeup。server采用异步的方式,由kernel mode唤醒fence等待队列。fence也分cpu类型和gpu类型。
display fence:软件fence,在flip时kernel mode发送。
调度优先级:优先级调度和先进先出,优先级只分两级,低和高。
- 中断:中断分为schedule(fence vsync busy)、power(pg cg dvfs)、display(热拔插 vsync)三大类,中断程序包括读中断和中断处理两部分
- 功能子系统:调试系统,例如内存分配、任务生命周期、内存分页等
OpenGL
-
OpenGL概述:opengl是一组应用层图形api,只是接口规范并不是具体实现,具体实现可走软件的mesa或vendor硬件实现。渲染管线包括:顶点绘制、图元 装配、光栅化、片段着色等基本流程, 对应着顶点着色器、细分着色器、几何着色器、片段着色器。
-
OpenGL编程步骤:利用EGL或GLFW等中间层窗口框架创建渲染窗口,OGL在其创建的window或者surface上绘制;定义并编译GLSL的pipeline渲染代码, 最少包括顶点着色器和片段着色器;然后在上下文中bind VBO、EBO等数据类型,VBO就是在显存中分配一个内存块,GPU只用从这里取数据不用一直改所以很快。 新版本的OGL可以将VBO bind到VAO上方便定义和切换,老版本需要在draw循环中bind VBO;然后获取纹理数据到纹理单元(1-16个),其中包括格式转换和 格式定义等;最后就是在循环中draw,清屏->激活VAO、 着色器->加载纹理->绘制->响应回调事件。
-
OpenGL坐标系统:屏幕零点坐标在中间,3D坐标系为右手坐标,z轴指向屏幕外,可视范围都在-1,1内。3D可视空间变换包括:模型矩阵、观察矩阵、 投影矩阵,模型矩阵的作用就是把物体放到合适的接近真实的大小和位置,观察矩阵就是看的方向和距离,投影(视角)矩阵就是截取视线角度和范围。 对于看不到的物体,可以开启深度测试,OpenGL会基于深度缓冲把绘制点与当前深度缓冲对比,丢弃小于它的点。
-
纹理:纹理就是细节图像,在VBO中可指定纹理坐标,纹理坐标和OpenGL的坐标不同,零点在左下角。可以通过设置一些纹理相关的宏实现不一样的效果, 比如环绕复制方式,采样方式等。GLSL中通过uniform类型传递纹理。
-
模板和帧缓冲:模板缓冲就是当前时刻存储一个固定矩阵,绘制时与固定矩阵加设置条件,这里设置条件可以任意,通常是绘制的位置模板值为1就不绘制。 绘制边框轮廓常用模板缓冲。帧缓冲就是数据内存,GLFW创建了默认帧缓冲,包括颜色、模板、深度的。可以通过glGenFramebuffers创建自定义帧缓冲, 然后给帧缓冲attach一个具体缓冲,最后分配renderbuffer数据(深度、模板)和texture数据内存。主循环要使用帧缓冲要bind加上具体数据,并和默认帧缓冲切换。
-
光照:光源叠加就是两个RGB相乘,对于被照物体就是在片段着色器上输出乘个颜色向量。冯氏光照模型包括环境光、(漫)反射光、镜面光,环境光就是光源 和物体即使不在也有一些光亮,漫反射就是光源对物体的影响,镜面光就是物体表面的影响。计算光照时距离不重要,方向重要,通过法线夹角计算漫反射, 镜面光由物体材质决定。光源属性包括点光源、平行光、距离衰减,多个光源、属性叠加也是相乘。
-
贴图:贴图就是纹理,传入的方式和纹理一样。光照贴图将采样值乘上光照分量有更真实的效果。
-
细分着色器:就是切点和线,增加点和线,可以自己定义分割方法,新增的点可以输入到几何着色器。
-
几何着色器:对传入的顶点进行连线,决定几何形状。学习网站实现了法向量可视化的example,就是在绘制每个三角平面时加一个法向量线。
-
其他:
3D model对象:通过一些组件网格组成可直接加载的大模型,每一个组件mesh都要实现draw,相当于一个一个组件画
blending:混合颜色,实现不透明的效果,可通过宏开启
面剔除:有一个宏控制,可剔除正向和反向面
立方体贴图:将6张图放在空间中,这一部分包括折射、反射的计算函数
高级数据:VBO中的数据改成自定义拼接格式
GLSL内建变量:内建变量就是提供了一些变量实现特殊的功能,比如点放大、自定义深度值、面剔除等。接口块就是一个结构体,uniform也有块结构。
实例化:用于复制对象,通过模型矩阵在世界空间生成大量实体。
gamma矫正:用非线性曲线表示色阶
抗锯齿:多重采样,一个光栅格子多个点
pixmap:基于ASCII编码的图像格式,其实也就是一张图片
阴影贴图:光线向量计算出阴影范围,深度贴图:视线到物体的距离,法线贴图:根据颜色值改变法线
PBR:基于物理定律的渲染,根据一些物理公式
调试错误查询glGetError,GLSL可以用颜色值调试输出
显卡知识
-
PCIE:是计算机地址总线的一种,pci的延伸,有更快的速率和带宽,pcie插槽通道有1、4、8、16。PCIE的传输协议跟网络包有点像,也有帧头帧尾、 插帧去帧的过程,PCIE设备开发针对交换层的信息包TLP。显卡属于pcie设备隶属于总线空间。总线号、设备号、功能号
-
PCIE地址空间:PCIE设备有四类内存:configure space、io space、memory space、message。在上点bios阶段会读取configure space的信息, 包括显卡厂商信号,硬件版本等信息,中间部分映射物理地址的叫bar需要填写,通过读取bar的位长确定空间大小(有一段值是写死的,判断写死的最高位然后确定空间大小), PCIE在memory低地址段有一段映射空间,映射DRAM(MMIO)到这里,这个空间叫IO地址空间,对于X86来说,IO采用独立编址,arm中的IO使用统一编址。为了兼容老版本的pci, memory空间中有相同的configure space。这里实现了cpu放内存或者io能访问到pcie域。
-
pci匹配:硬件信息在sys/bus/pci/devices下的uevent,总线驱动程序执行device_match_driver扫描 /lib/modules/uname -r/modules.alias,匹配MODAILAS变量中的pci信息。 pci维护了所有厂商的id表,系统需要更新这个表。
-
独显内存:MMIO的内存大小有时远小于独显内存,这是因为task中一次不需要这么大的dmabuffer,驱动不断的做新的dmabuffer并告诉gpu使用, 然后不断开新的buffer,只用转换显存其实地址就行。 core不直接访问显存,通过L2 cache和L1 cache访问。
-
cpu访问gpu:准备一个命令字,通过I/O端口或者MMIO映射的寄存器发送;利用MMIO做DMA把内存里的东西送到显存里;如果有返回命令,这里可能要等待DMA中断完成之类的动作; cpu通过总线地址映射访问gpu内存。
-
显卡硬件:显卡不像CPU一样处理很多条件判断或冒险,流水线要保证高并发才能处理大量数据。显卡核心SIMD相当于处理单元,里面包含很多stream processer(core) 也就是线程资源,下面包含渲染管线(就是OGL中的管线)。显卡还包括电源模块、3D渲染模块、VCP(编解码),VPP(加速),内存,display等。
-
display:framebuffer是硬件无关的抽象,plane(主平面、视频overlay、鼠标、背景等下层平面),crtc,显示器mode,vblank是留下一截空白部分 用于同步,防止画面撕裂。
-
Video:video driver,vaapi,vdpau
-
半导体:IP核,Fabless模式,IDM,IC流程,SOC(设计 制造 验证)。
-
串口调试:硬件需要串口转换线和usb转换线,启动的boot更改参数
EngineStatus_e3k能记录模块状态
-
内核调试:在内核模块中测试内核函数,printk打印内核消息,kgdb调试内核源码,公司驱动zx_info打印消息。
-
打log和看log:系统简易log看dmesg、查看驱动相关看kernel/debug、系统起来之前异常看串口log、Xorg看var/log
-
tool工具:gdb、debug-server
-
linux查看驱动信息的命令:
# link
ldd
nm -D
ldconfig (system load)
objdump/readelf
# 查看进程加载的库 cat /proc/\*/maps
# 上面一条命令能查看所有app走的pass-库
lsof -p PID
# Xorg
cat /var/log/Xorg.0.log
cat ./.local/share/xorg/Xorg.0.log
/usr/local/lib/xorg
cat /usr/share/X11/xorg.conf.d/\*
# Mem
cat /proc/iomem
# package
dpkg -l
sudo apt show
gdb call(函数 b函数) until(跳出 终止) catch(捕获系统调用) watch(改变就打印值) backtrace up/dowm
ps aux -ef
gdb 工具参考
FromWiki
- /proc/driver/dri0
- inxi
内核
-
mmio 外设映射到内存物理空间
-
iommu 外设访问cpu内存 通过引入gart表
-
io remap:__iomem 是一个宏定义,表示这段内存是用于 I/O 操作的,编译器会根据它来生成相应的代码,确保读写操作的正确性。 ioremap 函数的返回值是一个指向映射后的内核虚拟地址的指针。通过这个地址,内核可以直接访问硬件设备的寄存器和内存区域,实现对硬件设备的控制和数据传输。
-
驱动类型:字符设备、块设备、网络设备。内核模块、insmod
pci platform 物理结构 platform驱动是虚拟总线,实际上硬件并不存在,可用于所有的硬件平台, pci驱动,是硬件上实际存在的(pci bus),pci bus主要用于x86规范。 设备注册 需要手动调用platform_device_regster()函数进行注册, 而pci设备是linux内核在启动时会自动进行探测,然后注册到系统当中。 资源方式 platform驱动根据硬件启动,一般硬件成型以后资源就确定了,而pci驱动是bios 为设备进行的资源分配(irq,内存等) 设备和驱动的匹配方式 platform驱动是靠name匹配,pci驱动是靠table匹配。
-
字符设备:a char device and a regular file 可通过mmap 或者 lseek访问
-
内核锁:互斥锁(mutex) 自旋锁(spin) 读写锁 信号量 屏障(前面的不会到后面)
-
platform总线 描述硬件信息和资源 (io 中断 dma) arm(外设控制器,内存写死 不依赖总线了 SOC系统中集成的独立外设单元(I2C,LCD,SPI,RTC等)都被当作平台设备来处理,而它们本身是字符型设备。) pcie枚举探测
-
中断。硬中断(外 异步 中断处理程序不可抢占所有不能太长) 软中断(内 同步)。上半部 (硬件相关 紧急 不耗时) 下半部 tasklet(开一个线程 耗时 给数据地址) 注册中断 甚至使用工作队列。
-
semaphore mutex rwlock spinlock atomic RCU(grace period 有指针 读不敏感 no sleep 读拷贝更新) MB(读写顺序正确) Seqlock(write优先进) precpu就是静态分配一下
-
内存泄漏:用户态(mtrace valgrind)内核态(简单log:kmemleak slab crash/kdump)
kmemleak在debugfs中trace kmalloc事件 slab工具追踪某一个kmalloc生成的trace
-
makefile: $(filter %.o,$(obj_files)): %.o: %.c
one := $(patsubst %.o,%.c,$(foo)) # This is a shorthand for the above two := $(foo:%.o=%.c) # This is the suffix-only shorthand, and is also equivalent to the above. three := $(foo:.o=.c)
$(foreach var,list,text) text就是ops
legacy建立pipeline 
-
drm_mode_card_res drm_mode_get_plane_res drm_mode_get_connector
drm_mode_modeinfo drm_mode_get_encoder
简单点就是拿到crtc(硬件)选择plane(哪个) -
drm_mode_crtc
概要:通过kmalloc(),vmalloc(),kmem_cache_alloc()和friends分配的内存将被追踪,并将指针与大小和堆栈跟踪等附加信息一起存储在rbtree中。将跟踪相应的释放函数调用,并从kmemleak数据结构中删除指针。
如果通过扫描内存(包括已经保存值的寄存器)找不到指向其起始地址或块内任何位置的指针,则分配的存储块将表现为:orphan状态。这意味着内核可能无法将已分配块的地址传递给释放函数,因此该块被视为内存泄漏。
扫描算法的步骤: 一: 将所有对象标记为白色(其余的白色对象稍后将被视为孤立) 二: 从数据部分和堆栈开始扫描内存,根据存储在¨rbtree¨中的地址检查值。如果找到指向¨white object¨的指针,则该对象将添加到¨gray¨名单中 三: 扫描¨grey object¨以匹配地址(一些白色对象可以变为灰色并添加到灰色列表的末尾),直到¨gery list¨充满
其余的白色对象被认为是孤立的,并写到/ sys / kernel / debug / kmemleak
一些已分配的内存块的指针存储在内核的内部数据结构中(这部分 被封装的极好,不在rbtree中,换句话讲就是检测不到), 所以这部分指针所对应的¨object¨不能算作 ¨orphan object¨。
为了避免这种情况,kmemleak还可以存储指向需要找到的块地址范围内的地址的值的数量,这个块将视为非泄漏的。 __vmalloc()运用了此种机制。
EGL从nativedisplay获取EGLdisplay和driver
dri2_initialize_x11_dri3 -> dri3_x11_connect
通过Xdisplay获取到fd drm从fd中读信息
eglDisplay = eglGetDisplay(nativeDisplay); (dpy)
_EGLDisplay *disp = (_EGLDisplay *) dpy;
Display *dpy = disp->PlatformDisplay //这里的PlatformDisplay就是nativeDisplay
dpy->xcb->connection
xlib中的_XDisplay比系统头文件的_XDisplay显示成员更多,但其实就是一个地址
amd powerplay driver
-
amdgpu_device_ip_early_init : 初始化device
-
amd 的 adev其实就是把adapter放进去的card
-
amd engine 架构 和 arise 的不同:
-
arise 在adapter下有schmgr 里面每个scheduler manager包括了engine type和func amd 放在adev下的ip_block中 其中ip_block就相当于schmgr 其中的pp_ip_func 就是 chip_func
-
amd每个version engine的func和register单独放成文件
-
powerplay 有两种版本 |old|newfetch| |—|—| |attach pp_smu_ip_block | smu_v11_0_ip_block | |init_fuinc pp_ip_funcs|smu_ip_funcs | | touch on
pp_hwmgr *hwmgr pp_dpm_funcs(reserved power status and ctrl word)| touch onsmu_context swsmu_pm_funcs| |vi_set_ip_blocks(add chip ip/engine func) |amdgpu_discovery_set_ip_blocks(if asic has smu powerplay, then discovery old)|
| only choose one inpp_smu_ip_block(old_version) |smu_v11_0_ip_block(new_version) // both chip func not method func| | pp_dpm_funcs | swsmu_pm_funcs | // method chip rela |->hwmgr_func = &smu10_hwmgr_funcs|->ppt_funcs = &smu_v13_0_0_ppt_funcs| ->amdgpu_dpm_force_performance_level(ctrl logic unrelative chip) /amdgpu_device_ip_set_clockgating_state-> chip_func// select suitable engine smu_v13_0_0_ppt_funcs is swsmu_pm_funcs specific implement,during init period paste to sum_context
-> common_interface-> smu_adjust_power_state_dynamic -> smu_asic_set_performance_level -> smu_v13_0_set_performance_level ->smu_v13_0_set_soft_freq_limited_range->smu_cmn_send_smc_msg_with_param
chip 无关函数 -> sum自身的函数 -> sum chip相关的函数 hwmgr与chip相关的函数->hwmgr_func = &smu10_hwmgr_funcs //挂在hwmgrfunc下 ppfunc挂的简单 smu与chip相关的函数->ppt_funcs = &smu_v13_0_0_ppt_funcs //挂在smu的ppfunc下 事实上,smu的pptable就很复杂了
Intel i915 driver power
i915 powergating 很简单只有在init阶段写reg intel 的powermanager 只是简单的提前上电,优化速率
架构介绍 (https://zhuanlan.zhihu.com/p/626636620)
Front end, GPC, EU(slice), CS(core)
Front end 将数据简单切分给GPC,例如图片划分8*8
GPC 处理数据的主要zone
EU slice包括很多core,SIMD可以分为32 甚至是64,超多线程处理
E3 slice分成了PE和其他组件
Wave就跟Warp差不多,细分数据计算 分包(每个Warp对应32个顶点,交由SM里32个线程并行执行VS处理)
Poly Morph Engine: 通过三角形索引(Vertex Fetch)取出三角形的数据(vertex data)
这样顶点着色器相当于就是视角着色器
(https://developer.nvidia.com/content/life-triangle-nvidias-logical-pipeline)
Raster 之后重回 GPU进行pixel/frame
光栅化阶段 根据bo大小划分片元
BO内存分配
gem_create_allocation 只是分配一个bo Description在ram,通过gem函数drm_gem_private_object_init将bo关联gpu
在绑定到dma-buf或者手动map到gpu的时候,进行alloc_page分配paga,提升为dma类型的page
- pcie memory: 分配完全按照cpu的分配方式,不过是增加了天gart表的过程。先分虚拟地址,mmu出现pagefault的时候回调处理函数,例如vm_ops的gem_fault
- local memory: 在submit_dma_task/vm_map_gpu_virtual_address(理解这两个时刻,一个是向下发 一个是向上提交)的时候就将make_unpageable的内存的pte表填了,之前都是没有任何local memory分配的
- vidmmi_vm_allocate_node 分配vm_node 就是虚拟地址
- 最终实现在vidmmi_allocate_fb_page_memory 最後調的函數還是drm的helper的 例如drm_mm_search_free_in_range_generic
- 如果分配的内存在主存,zx_allocate_pages_memory_priv -> 最終page_alloc分,如果在显存,zx_drm_mm_ra_alloc-> 最终drm_mm_insert_node_in_range
- 最后vidmm_allocation_update_mapping 将物理地址关联虚拟地址 填写pte
cache一致性
LLC Lastly Level Cache:每次更改硬件自动写回到cache GPU可能需要软件下command维持一致性的例子,在不同GPC中,1. 出现2D 3D切换 2. tile下格式变化 重新同 步
2D driver
在我们driver中
2D driver的入口定义为_X_EXPORT XF86ModuleData amdgpuModuleData, ModuleData前面就跟_drv相同,也有就是从drm独到的VersionInfo
在Xorg中
Xorg loadmod的过程:先调FindModule找到.so 再调dlopen 组装cx4ModuleData结构,调用dlsym(fd,function) 印象中是先加载所有的drv driver然后再删 判断依据是xf86IsEntityPrimary 整个流程都在DoConfigure中 所有的初始化阶段都看这个函数 在drive中,也有opendevice 和 allocatescreen
InitOutput(&screenInfo, argc, argv); //加载drv 其中LoaderOpen加载库
if (screenInfo.numScreens < 1) //加载dri
FatalError("no screens found");
InitExtensions(argc, argv);
Xorg中的通信
epoll + socket(socket在内核中记了@/tmp/.X11-unix/X0 对应文件系统的/tmp/.X11-unix/X0)
可以通过 ss -ap | grep Xorg查看
fence中斷
fence相關包括:
fence綫程 signaled fence(primary bo),处理fence线程状(回来了没有)
fence wait_queue(wake_up 唤醒所有的在给定队列上等待的进程)
fence中斷響應(zx_notify_fence_interrupt,更新fenceid,唤醒wait event)
fence_id 和 dma_fence
上述函數命名可能來源於Glenfly Amd Nvidia數據手冊或者文檔,但是都基於開源代碼